

Naming conventions are a very subjective thing, of course. Just like coding styles, they can often lead to anything from minor debates to full-blown religious arguments. Upper case vs. lower case keywords, tabs vs. spaces, and where to put commas come to mind. Heck, these same people even get into sub-arguments about whether the terms “upper case” and “lower case” should use hyphens, spaces, or neither. I’ve long been a proponent of not caring about which naming standards you use, but I do find it very important that your standards follow these three basic rules:
- The conventions make sense. You should be able to argue why the chosen convention is better than an alternative, and it can’t just be because you like it better. This doesn’t mean you have to win that argument, just that you should be arguing for something tangible.
- The entire team is on board. You should all agree on a standard before implementation, and any changes you make over time should be by committee.
- You don’t make exceptions. Even if you’re a one-person team, if you’re going to bother having a standard, it needs to be used consistently. It’s amazing how quickly exceptions can become the new rules.
That said, that doesn’t mean I don’t have opinions.  There were a few things in Sehrope’s article that make a little less sense to me, and I’m prepared to argue why – particularly where the scope is limited to SQL Server. Of course, if your conventions need to cover multiple platforms and not just SQL Server, then some of my arguments may carry less weight.
There were a few things in Sehrope’s article that make a little less sense to me, and I’m prepared to argue why – particularly where the scope is limited to SQL Server. Of course, if your conventions need to cover multiple platforms and not just SQL Server, then some of my arguments may carry less weight.
TL ; DR VERSION
Since I know some of you like to minimize reading and scrolling, I’ll sum up my counter-points to the post:
- In SQL Server, identifiers do not need to be all lower case to avoid quoted identifiers, and hence snake case is unnecessary, too. Snake case also introduces issues for some of Sehrope’s other conventions.
- A table is a set of things, and therefore should be named plural rather than singular – even if, sometimes, a table might only have one row.
- Single-column keys should not be named
id– if it’s aCustomerID, it should be calledCustomerIDalways, not most of the time. - It’s not practical or necessary to always include both table names, all column names, and the type of constraint in a foreign key constraint name.
- It’s not practical or necessary to always include the table name and the type of constraint in a check constraint name.
- Some of Sehrope’s points conflict with each other, such as the use of namespace prefixes.
Read on for more details. I would have commented on the page directly, but it’s an older post, I’m not sure if comments are moderated properly, and I am certain I would exceed the max length of a comment anyway.
“Identifiers should use lower and snake case”
Sehrope argues that identifiers should always be in all lower case, and visual separation should be achieved through underscores (“snake case”). The reason for lower case is that, on some platforms, mixed or upper case names require quoted identifiers. This is not true in SQL Server, so forcing lower case can actually hamper readability. Subjective, sure, but I don’t agree that a junction table like book_authors is more readable, or easier to type, than BookAuthors. The underscores add some space between the words, which can aid readability for some, but it can work against you when reading in a fixed-width font (it can look like two separate words) or when the identifier is in documentation and underlined (the underscore disappears).
Mixed case does require some care when coding, though. On case insensitive systems, mistakes are easy to miss, especially if names aren’t provided through tools like IntelliSense (which takes the case directly from the metadata). And there will be serious problems if those mistakes make it through to a deployment onto a case sensitive system.
I do have one exception where I like snake case: procedure names. Unlike entities, most stored procedures have two very different parts: an object and a verb. My preference is object_verb, e.g. BookAuthors_Update, so that I can immediately identify the entity the procedure(s) act on, and can then move on to the action they take. This pays off best in sorted lists, such as Object Explorer, where I am often scanning for the stored procedures that involve BookAuthors. Some people like naming conventions like verb_object, e.g. Update_BookAuthors, but then that makes all the stored procedures that perform updates on any entity sort together, which is rarely useful.
“Table Names Should be Singular”
By definition, a table is a set of things, even if in some cases that set only has one member. And in all of the apps I’ve worked with since the 1990s, that scenario is pretty rare, never mind permanent. It’s unlikely there are many convincing use cases where a table is meant to only have a single row. So, in my opinion, as long as you can avoid getting hung up on how to pluralize an entity name, table names should be plural. This is because when you speak about a set of things naturally, you use the plural form. When you come home with a bag full of stuff from the grocery store, it is a bag of groceries, not a bag of grocery.
Sehrope debates whether a table – where each row represents a person – should be called Persons or People. I would probably go with the irregular plural People, or something more specific, like Members, Users, or Customers. If the goal was to avoid plurals that end with s, then you could go with Membership, Staff, or Userbase. Celko would likely opt for Personnel, and why not? It’s what ISO once used as an example. From a former version of ISO 11179:
Tables are Collections of Entities, and follow Collection naming guidelines. Ideally, a collective name is used: eg., Personnel. Plural is also correct: Employees. Incorrect names include: Employee, tblEmployee, and EmployeeTable.
“Single-Column Keys Should Be Called id”
This is probably the convention I feel strongest about. Contrary to Sehrope’s advice, I think that, when possible, an entity should be named the same thing throughout the schema. Yes, this means that you’re using a prefix as a sort of namespace, but this is happening in every other related table anyway. This goes back to my bullets about consistency and exceptions. No matter how convoluted your joins and aliases are, you can always tell which id is being referenced in a query because it will be named explicitly.
Having a full name in the primary table (say, Customers.CustomerID instead of Customers.id) also makes it much easier to find all the related instances. If you have the quandary above about People vs. Persons and the 15 other ways such a table might be named, and you just named the PK id, what column name are you looking for in the rest of the metadata? If using id means you don’t have to worry about what you would actually call that name if you wanted a full reference (like PeopleID or PersonID), this doesn’t really buy you anything except that it allows you to slightly defer that decision until you create the first related table, because that column can’t simply be called id.
“Foreign Key Names Should Include All Column Names”
Sehrope suggests that the name of a foreign key constraint should be self-documenting, by including all of the column names in the constraint name. The example he used was where the team_member table referenced the team table, using the id column, and the foreign key name he preferred was team_member_team_id_fkey. On quick glance you might see a problem: This makes snake-cased object names a much harder sell, because now the underscores serve multiple purposes – it can be hard to distinguish when they are being used to separate tables from each other, are just natural parts of table names or, in the case of a multi-column key, to separate columns from each other, or are just natural parts of column names. (This is more about strengthening the argument against snake case in entity names, not arguing against snake case in constraint names.)
Fictitiously, let’s say we love snake case, and have tables foo_team and bar_group, with a multi-column key on (foo_id, bar_group_team_name). Under the proposed rule, a foreign key constraint relating the two tables might then be named bar_group_foo_team_foo_id_bar_group_team_name_fkey. While I agree that single-column keys are the majority by a great margin, the potential for this kind of mess is just one of those exceptions I can’t get behind. Further to not being able to easily parse and understand that name, you can also get into issues if you have particularly long table and column names – identifier rules in SQL Server dictate that you’re capped at 128 characters.
I also find the _fkey suffix unnecessary (and violates a major section title in Sehrope’s article: “Prefixes and Suffixes (are bad)”). If you’re researching the schema, you get foreign keys from very specific metadata views, so there is no confusion about what type of constraint you are looking at. And when you are troubleshooting an error message in real time:
Msg 547, Level 16, State 0
The INSERT statement conflicted with the FOREIGN KEY constraint “bar_group_foo_team_foo_id_bar_group_team_name_fkey”. The conflict occurred in database “demo”, table “dbo.foo_team”.
The statement has been terminated.
There’s nothing useful in that error message that you couldn’t also have determined if the constraint were simply named bar_group_references_foo_team.
“Index Names Should Include all Column Names”
Similar to foreign keys, the author argues that indexes should be self-documenting by including the names of all of the columns present in the index. But also as with foreign keys, this can become a real tough thing to pull off, given the 128-character limitation (and the issues with snake case). For specific, narrow indexes you probably won’t run into any problems, but in many scenarios (especially reporting systems), this will be much more difficult.
In addition, to make an index name fully self-documenting, we’re not usually just talking about a generic list of columns. There are many other attributes of an index that I would have to go look up anyway, and often these things are more important than just the list of columns. A quick rundown off the cuff:
- Is a column is in the key or in the include list?
- Is each column in the key ascending or descending?
- Is the index clustered or non-clustered?
- Is the index unique? (Related: Is it a unique constraint implemented as an index?)
- Does the index have any filter predicates?
- Does the index contain any LOB columns?
- Are the statistics for the index up to date?
- Is it a special type of index, such as XML, Geography/Geometry, or ColumnStore?
- Is the index on the primary filegroup?
- Is the index partition-aligned?
- For in-memory indexes, is it a hash index, and if so, what is the bucket size?
I’m not suggesting that I would want all of those things represented in the index name, because then we’d need a heck of a lot more than 128 characters. I’m just demonstrating that if I’m doing any kind of performance tuning or index analysis, having slightly faster access to the column names doesn’t prevent me from having to go and do a bunch of research about the index anyway. This would probably work fine in the simple, narrow index case (in which case maybe it’s okay for the index name to indicate the leading key column), but breaks down quickly when any of these other factors come into play.
Like with foreign keys, I find the ix identifier in the name unnecessary. I’m trying to envision a scenario when I’m looking at an entity name and I don’t already know it’s an index – certainly not when I’m looking at an execution plan or analyzing the indexes on a table.
Inconsistencies
This may seem a bit nit-picky, but the author talks about using id instead of, say, PersonID, in order to avoid using a prefix as a sort of namespace; he also suggests to avoid using all but the most common abbreviations. Then the check constraint he shows toward the end of the post is named person_ck_email_lower_case. Why ck instead of check? I’m not sure how common ck is as an abbreviation, nor am I sure that either ck or check is necessary (for the same reasons fkey is not necessary in a foreign key constraint name, and ix is not necessary in an index name). If a constraint violation occurs, it’s going to be pretty obvious what type of violation happened, and it also makes the table reference redundant because the error message will state which table had the violation. Here is an example of a check constraint violation:
Msg 547, Level 16, State 0
The INSERT statement conflicted with the CHECK constraint “person_ck_email_lower_case”. The conflict occurred in database “demo”, table “dbo.person”, column ’email’.
The statement has been terminated.
So, having the table name in the constraint name is redundant, and doesn’t add any value during troubleshooting. He repeats this namespace prefix in index names (e.g. person_ix_first_name_last_name) – here, too, the leading table name is redundant; I can’t picture a scenario where I’ll be looking at an execution plan and not know which table an index belongs to (these things are paired together intentionally in both the XML and the graphical plans). Here’s an example using SQL Sentry Plan Explorer:
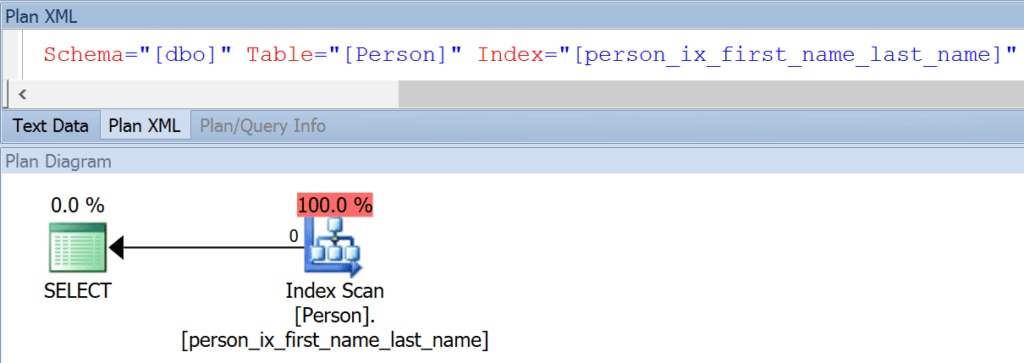
Redundancy in XML and graphical plan
Unless I am being intentionally obtuse, there’s no way for me to not know which table belongs to that index.
CONCLUSION
I don’t expect you to agree with all of my points here; in fact I’d be kind of disappointed if you did. Also, I hope this isn’t interpreted as a slam on Sehrope’s post, which I really think is a valuable read no matter what platform you use. This can be a touchy subject with no right answers, and with a lot of opinion and bias inevitably shaping decisions. I just wanted to illustrate the thinking behind some of the naming standards choices I make.
