SolarWinds SQL Sentry
Database performance monitoring for SQL Server and Azure SQL databases, with fast root cause analysis and visibility across the data estate
Starts at
Subscription and Volume licensing options available
Monitor. Diagnose. Optimize.
Go from reactive database firefighting mode to proactively optimizing data system performance.
Actionable Performance Metrics
Monitor all aspects of your environment from a single dashboard display
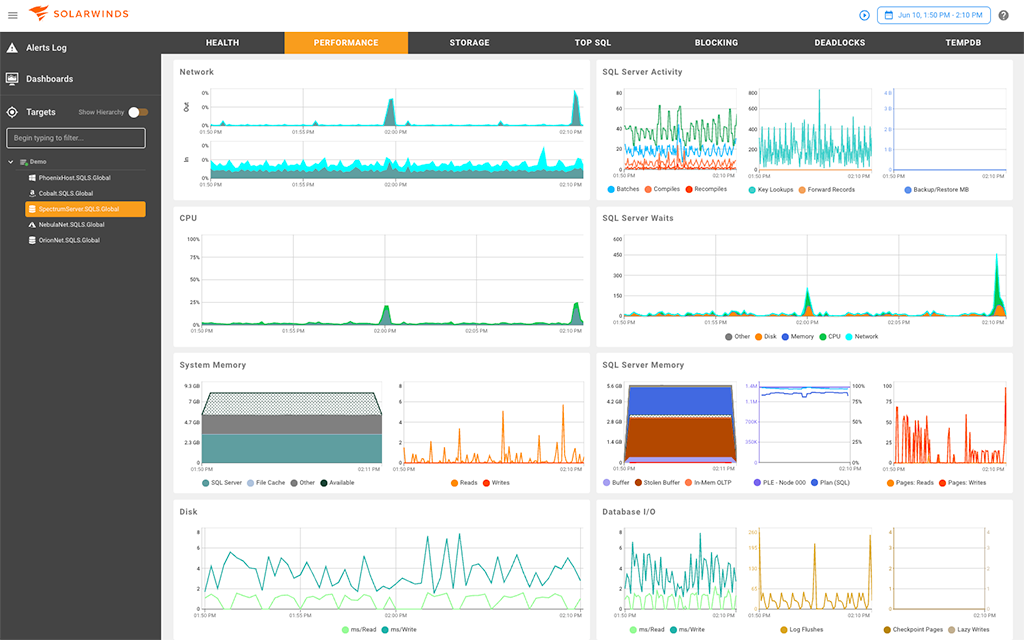
An at-a-glance view of important database environment performance metrics
SQL Sentry Performance Analysis Dashboard offers a quick snapshot of Microsoft data platform health. Drill down for root cause analysis of performance issues.
Advanced Alerting
Intelligent alerts can warn you about database performance problems
Query And Index Analysis
Optimize and tune SQL query performance
Storage Forecasting
Prevent business interruptions with Storage Forecasting powered by predictive analytics
SQL Sentry Portal
Access performance data from a web browser
SQL Server Deadlock Monitoring
Quickly diagnose and resolve SQL Server deadlocks
Gain visibility across your Microsoft database environment





Get in-depth insights. Download the datasheet today.